Natural Language Image Search with Visual Language Models (VLMs)
Overview
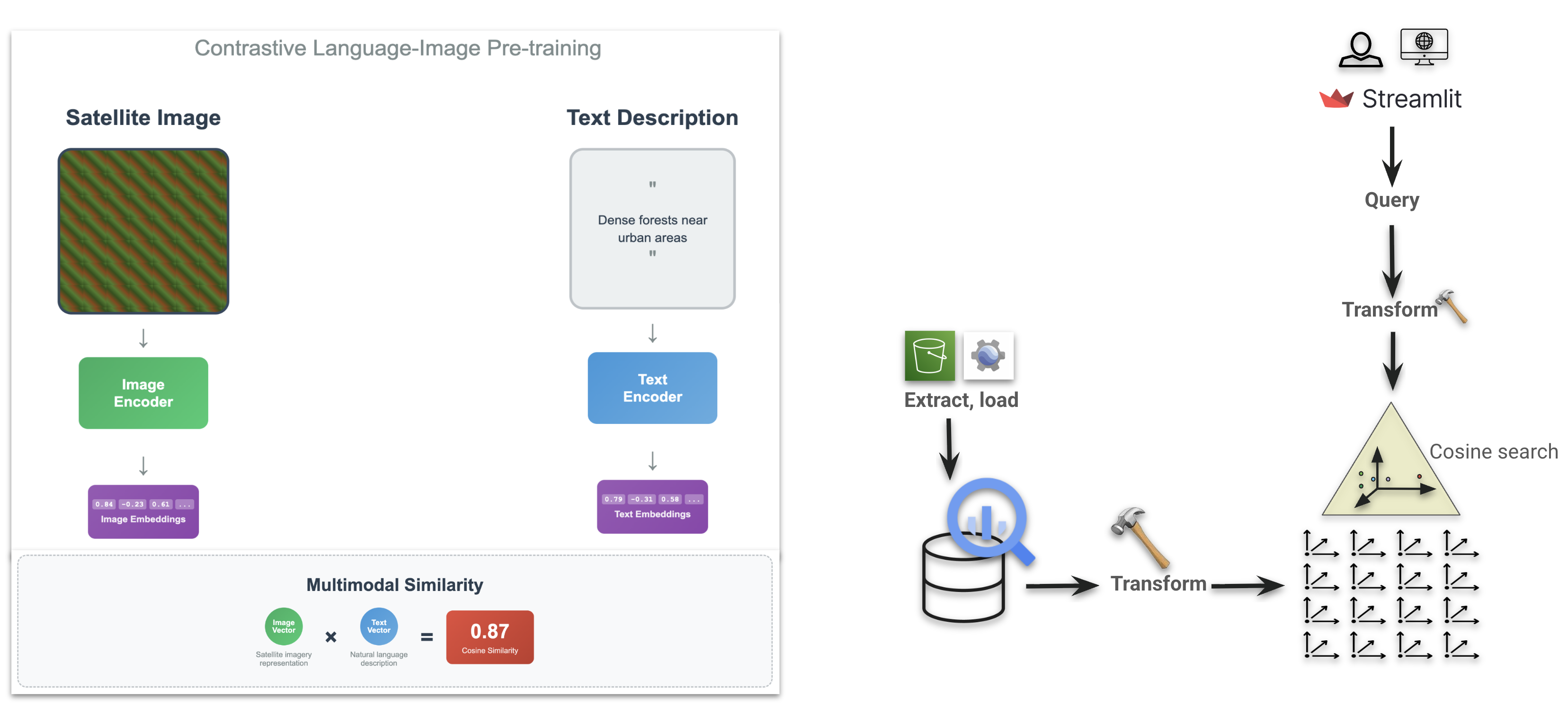
This project demonstrates how Visual Language Models (VLMs) can be used to perform text-to-image search over geospatial data. Using NAIP imagery, I created embeddings for image tiles and stored them in BigQuery. Queries are processed via a text encoder, and similarity is computed between text and image embeddings to return the most relevant imagery.
Unlike the previous project (where embeddings were provided directly), this workflow involved generating embeddings end-to-end:
- Exporting imagery from Google Earth Engine.
- Passing tiles through an open-source VLM from Stanford, fine-tuned on satellite imagery + OpenStreetMap tags (a CLIP variant).
- Building a vector index in BigQuery for scalable similarity search.
- Developing a Streamlit UI to enable interactive natural language queries such as “planes on a runway” or “isolated tree in a field.”
Key Components
- Data Preparation – NAIP imagery exported via Earth Engine.
- Embedding Generation – Applied Stanford’s CLIP-based geospatial VLM to produce image and text embeddings.
- Vector Database – Stored embeddings in BigQuery with partitioning and indexing for efficient similarity search.
- Custom UI – Built a Streamlit app for user queries and real-time result visualization, with imagery tiles served via Google Cloud Storage.
Applications
- Semantic image retrieval using natural language (beyond keyword-based search).
- Label bootstrapping for machine learning workflows.
- Exploration of topological features (e.g., single trees, roads, urban structures) directly from text.
- Improved accessibility of large-scale Earth observation archives for non-technical users.